.jpg?width=1813&height=490&upsize=true&upscale=true&name=shutterstock_2509369399%20(1).jpg)
Large Language Models (LLMs) such as Claude, Gemini, and GPT have emerged as the mainstay of today's AI-powered businesses. Many of the intelligent workflows driving digital transformation are powered by LLMs, from decision-support systems to intelligent chatbots and automated content creation.
However, even the most powerful models face a subtle yet growing threat: data drift.
Unlike visible system failures, data drift operates quietly in the background. It gradually impairs model performance, introduces bias, and lowers user confidence while providing the results. Businesses must not only identify drift early on but also create robust systems that can adjust to it in a world where data is constantly changing in terms of language, social context, and context.
What is Data Drift in LLMs?
At its core, Data Drift refers to a change in the statistical properties of input data that differ from the data the model was trained on. When the patterns in real-world usage evolve beyond what the model knows, its understanding starts to decline.
LLMs are trained on large datasets that capture a snapshot of the world, including its language, knowledge, and norms, up to a certain point in time. However, language, culture, and industry contexts are always changing.

"Figure 1When real-world language evolves beyond the model’s training horizon, drift begins.”
Types of Drift
- Covariate Drift:
The distribution of input features (like words or phrases) changes. For example, financial terminology is evolving with the introduction of new market instruments. - Concept Drift:
The relationship between input and output changes. For example, the meaning of AI safety in 2021 might differ from its meaning in 2025. - Label Drift:
The interpretation of target outcomes shifts, especially in supervised fine-tuning scenarios (e.g., “positive sentiment” toward a new product).
Everyday Examples
- A retail chatbot trained on “Black Friday” deals fails to interpret “AI Week” promotions.
- A healthcare assistant misunderstands new drug names not present during training.
- A financial model misinterprets new ESG (Environmental, Social, Governance) reporting terms.
Why Data Drift is a Silent Performance Killer
One of the most significant dangers of data drift is its gradual and often invisible nature. Unlike code bugs or system outages that announce themselves through errors, drift creeps in quietly. It begins as subtle inaccuracies in responses and slowly erodes a model’s effectiveness, credibility, and alignment with current reality.
1. Decline in Response Accuracy and Relevance
As an LLM encounters inputs that no longer resemble its training data, its internal representations become less effective at mapping those inputs to meaningful outputs. What follows is a steady drop in relevance and factual correctness.
- Misinterpretations: The model starts misunderstanding new or evolving terms — for instance, confusing “agentic AI” (a new paradigm of autonomous systems) with “AI agents” or even “travel agents.”
- Hallucinations: When faced with unfamiliar topics, it may fabricate explanations that sound confident but are factually baseless, attempting to “fill in the blanks” from outdated context.
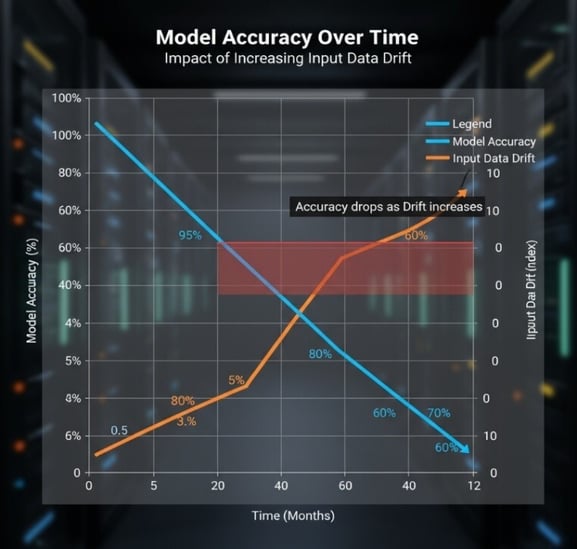
Minor inaccuracies can have significant negative consequences. In customer support, a single incorrect response can mislead users. In healthcare or finance, such errors can lead to substantial real-world risks.
2. Erosion of User Trust
Trust represents a critical and fragile component of any AI-powered system. When users perceive a model as unreliable, their behaviour changes rapidly. Users may verify AI-generated responses, disengage from the system, or return to manual processes.
- Reduced Engagement: Loss of user confidence results in decreased interaction, fewer data signals, and disruption of feedback mechanisms necessary for model improvement.
- Reputational Damage: In enterprise settings, persistent inaccuracies can tarnish brand reputation — the AI becomes synonymous with poor quality, even if the underlying technology is sound.
This erosion of trust is especially hard to reverse. Even after a retraining effort corrects the issue, regaining user confidence requires transparency, validation, and time.
3. Ethical and Bias Amplification
One of the most insidious and socially significant impacts of data drift is the amplification of bias. As models are trained on past data and not updated frequently, they remain stuck with outdated worldviews and language patterns.
- Reinforcing Old Stereotypes: The model is still producing answers that carry social biases contained in its initial data, despite society's growing understanding.
- Missing Linguistic Shifts toward Inclusivity: Drift will lead the model to miss or misunderstand new, inclusive expressions, from gender-neutral pronouns to culturally sensitive language.
Ethical drift doesn’t harm trust; it places companies at risk of regulatory and reputational harm, particularly as international AI governance systems increasingly focus on fairness, transparency, and social responsibility.
Detecting and Quantifying Data Drift
Effective mitigation starts with drift detection frameworks that continuously monitor both the input and the model’s output.
Key Detection Techniques
| Metric/Method | Purpose | Example Use |
|---|---|---|
| Population Stability Index (PSI) | Measures change in feature distribution | Comparing new inputs vs. training data |
| KL Divergence / Jensen–Shannon Divergence | Quantifies distributional divergence | Detecting new slang or vocabulary shifts |
| Performance Metrics (BLEU, ROUGE, F1) | Tracks output quality | Decline in relevance/accuracy of generated responses |
| Human Feedback Loops | Captures qualitative drift | Tracking downvotes or corrections from users |
Mitigating the Drift: Strategies for Building Resilient LLMs
Data drift is not a sign of failure—it’s evidence of a changing world.
Data drift is inevitable, but its effects can be lessened with active monitoring, adaptive retraining, and human guidance. Considering LLM as a living entity, one that grows with data, guarantees long-term dependability and trust.
1. Continuous Model Training and Fine-Tuning
Regularly exposing the model to new, high-quality data keeps it in tune with language and trends in the real world.
- Automated Retraining: Establish pipelines that regularly fine-tune the model on current, curated data.
- Efficient Learning: Utilize techniques such as LoRA or PEFT to fine-tune model parameters without training from scratch—conserving compute and maintaining core knowledge.
- Curated Data: Prioritize quality over quantity; cut noise and concentrate on domain-specific instances.
2. Robust Drift Detection and Monitoring
Build strong AI observability to detect changes before they affect users. This will mitigate drift to some extent.
- Track Input Patterns: Employ measurements such as Population Stability Index (PSI) or Jensen–Shannon Divergence to detect changes in language or phrasing.
- Monitor Output Quality: Regularly check model precision, relativity, and user satisfaction ratings.
- Set Alerts: Utilize observability tools (e.g., WhyLabs, Arize AI, Weights & Biases) to alert when drift exceeds thresholds and retrain accordingly.
3. Human-in-the-Loop (HITL) Validation
By using automation to manage the Drift issue and human expertise to govern the most critical outputs and inputs (precision), organizations can effectively mitigate Data Drift and maintain a high-performing, trustworthy AI product. Use expert review when the stakes are high or confidence is low.
- Validate Low-Confidence Outputs: Route uncertain responses to human reviewers.
- Domain Oversight: Have healthcare, finance, or legal experts review periodic samples.
- Feedback Loops: Pass human corrections back into the training data so the model improves constantly.
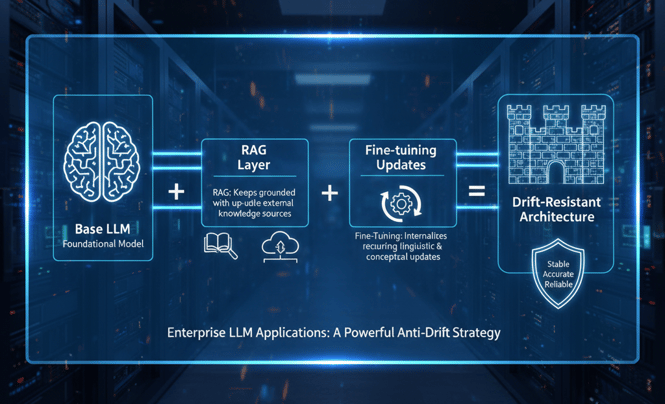
4. Hybrid Architecture: RAG + Fine-Tuning
Blending Retrieval-Augmented Generation (RAG) with fine-tuning provides both adaptability and factual grounding.
- RAG: Binds the model to live knowledge sources for up-to-date information.
- Fine-Tuning: Refines the model’s internal understanding of evolving semantics and tone. Together, they create a drift-resistant system that stays contextually aware and factually accurate.
5. Governance and Continuous Improvement
Sustained resilience requires process discipline, not just technology. It means establishing transparent governance, documentation, and accountability around every model update — ensuring that drift management becomes an organizational habit, not an occasional fix.
- Version Control & Lineage Tracking: Maintain clear records of data sources, model versions, and retraining cycles.
- Transparency: Log updates and performance metrics for compliance and auditability.
- Collaborative Culture: Incorporate drift detection into your MLOps process, an ongoing cycle of learning, testing, and optimization.
Conclusion
With LLMs becoming deeply integrated into key enterprise infrastructure, continuous learning becomes a non-negotiable requirement. The future will benefit AI ecosystems that can heal themselves, are drift-aware, and adapt contextually.

We’re entering an era where model freshness will matter as much as model size.Companies such as Coforge that recognise drift detection as an issue at an early stage, find ways to identify and mitigate it, will power the next generation of robust, enterprise-grade AI. Data drift is not a sign of failure—it’s evidence of a changing world.
The challenge is not to eliminate drift, but to evolve with it.
Through a blend of constant monitoring, adaptive retraining, and human oversight, companies can keep their LLMs as dynamic as the data they process.
Visit Quasar AI to know more.
- Data drift in LLMs refers to changes in input data that deviate from training data, impacting model performance.
- Types of drift include covariate, concept, and label drift.
- Drift leads to reduced accuracy, trust erosion, and ethical risks.
- Detection methods include PSI, KL Divergence, and human feedback loops.
- Mitigation strategies involve continuous training, HITL validation, and hybrid architectures like RAG + fine-tuning.
Q1: What is data drift in LLMs?
A: A change in the statistical properties of input data that differs from the model’s training data.
Q2: How does data drift affect LLM performance?
A: It reduces accuracy, increases hallucinations, and erodes user trust.
Q3: What are common types of data drift?
A: Covariate drift, concept drift, and label drift.
Q4: How can data drift be detected?
A: Using metrics like PSI, KL Divergence, and human feedback loops.
Q5: What are best practices to mitigate data drift?
A: Continuous fine-tuning, human-in-the-loop validation, and hybrid architectures.
- Covariate Drift: Change in input feature distribution.
- Concept Drift: Change in the relationship between input and output.
- Label Drift: Shift in interpretation of target outcomes.
- PSI (Population Stability Index): Metric to detect feature distribution changes.
- RAG (Retrieval-Augmented Generation): Combines retrieval of external data with generation for factual accuracy.
- LoRA / PEFT: Efficient fine-tuning techniques for LLMs.
Best Practices
- Use curated, domain-specific data for retraining.
- Implement continuous monitoring with PSI and divergence metrics.
- Incorporate human-in-the-loop validation for critical outputs.
- Maintain version control and transparency in model updates.
Common Pitfalls
- Ignoring subtle drift signals until performance drops.
- Over-relying on automated retraining without human oversight.
- Using noisy or irrelevant data for fine-tuning.

Khushboo Goyal is a Senior Consultant at Coforge with over 18 years of industry experience. A specialist in Agentic AI and Generative AI, she focuses on building autonomous frameworks, Virtual Assistants, and advanced RAG architectures. With a strong foundation in Machine Learning, Khushboo Goyal consults in strategic AI initiatives to deliver high-impact, practical enterprise solutions.
Related reads



About Coforge
We are a global digital services and solutions provider, who leverage emerging technologies and deep domain expertise to deliver real-world business impact for our clients. A focus on very select industries, a detailed understanding of the underlying processes of those industries, and partnerships with leading platforms provide us with a distinct perspective. We lead with our product engineering approach and leverage Cloud, Data, Integration, and Automation technologies to transform client businesses into intelligent, high-growth enterprises. Our proprietary platforms power critical business processes across our core verticals. We are located in 23 countries with 30 delivery centers across nine countries.