
In today's AI landscape, Large Language Models (LLMs) have emerged as powerful tools capable of generating remarkably human-like text. These sophisticated systems, built upon billions of parameters and trained on diverse datasets, come in various forms. From text-only models to multimodal systems handling text and images, from specialized medical and financial models to general-purpose AI, the ecosystem spans open-source solutions like Vicuna and proprietary offerings from tech giants like AWS, Azure, and Google.
The Challenge of Domain Expertise
The conventional approach has relied on comprehensive models like Anthropic Claude or GPT-4 to tackle complex use cases that span multiple financial and medical domains. While these models boast an impressive breadth of knowledge, they often struggle with nuanced, domain-specific queries unless supplied with extensive context.
This limitation presents a significant challenge: providing detailed context for every query affects performance and substantially impacts costs. As organizations scale their LLM usage, the financial implications become increasingly important. Each query accompanied by substantial context data adds to the operational costs, creating a pressing need for more efficient solutions. Companies find themselves walking a tightrope between maintaining high-quality responses and managing expenses.
Enter LLM Routing
This is where LLM Routing emerges as a game-changing methodology. Routing systems optimize accuracy and cost efficiency by intelligently directing queries to the most appropriate model based on the task. The router analyzes the query's context and intent, ensuring it reaches the most suitable model for processing.
The Power of Specialization Implementing effective routing requires a deep understanding of each model's strengths. For instance:
- GPT-4 might excel at creative writing tasks
- Claude could be the go-to for ethical considerations
- BioBERT specializes in medical queries
- Codex shows superior performance in code generation
By leveraging these specialized capabilities through intelligent routing, organizations can achieve optimal performance while maintaining cost efficiency.
For instance
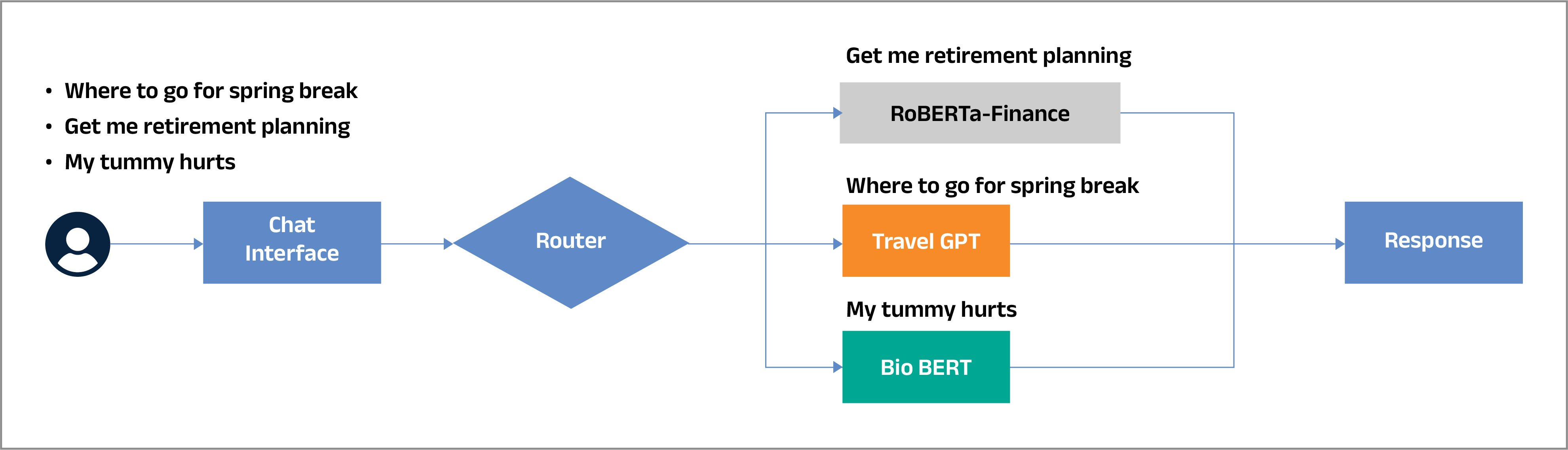
If we are developing a generic chat interface considering the most queried subjects of today’s world, a financial advisor chatbot, a medical diagnosis assistant, and a travel planning, then the router should understand the intent, classify the queries, and direct them to appropriate models as represented in the figure below.
In such scenarios, the router serves as an intelligent traffic controller, analyzing incoming queries to understand their intent and context. Based on this analysis, it directs each query to the most appropriate specialized model. This targeted routing ensures optimal response quality while maintaining cost efficiency.
Industry Solutions
Leading cloud providers are already recognizing the importance of LLM routing. Amazon Bedrock, for instance, has implemented sophisticated prompt routing capabilities within model families. Their system allows seamless routing between Anthropic's models (Claude 3 Haiku and Claude 3.5 Sonnet) and Meta's offerings (Llama 3.1 8B Instruct and Llama 3.1 70B Instruct), demonstrating the growing industry adoption of this approach.
Implementation and Future Horizons
Implementing LLM Routing represents a significant step forward in AI resource optimization. However, success requires careful consideration of several factors: maintaining up-to-date model profiles, establishing clear routing criteria, and implementing robust monitoring systems to validate routing decisions. As the LLM landscape evolves with new specialized models emerging regularly, dynamic routing systems will become increasingly sophisticated.
Innovation in action
At Coforge, we maintain our commitment to innovation in GenAI. We're working to enhance our solution's efficiency, accuracy, and cost-effectiveness by continuously exploring and implementing advanced methodologies in GenAI and AI.
Visit Quasar to know more.
Key Takeaways
- Traditional large, general-purpose LLMs struggle with highly specialized, domain-specific queries without extensive context.
- Providing detailed context for every query significantly increases processing costs and impacts scalability.
- LLM Routing intelligently directs each query to the most suitable model, balancing accuracy, efficiency, and cost.
- Specialized models (e.g., BioBERT for medical, Codex for code) enhance output quality when correctly routed.
- Cloud providers like Amazon Bedrock are already implementing sophisticated routing across Anthropic and Meta models.
- Dynamic routing requires maintaining accurate model profiles, establishing routing rules, and continuous monitoring.
- As new specialized models emerge, routing systems will become increasingly important for operational efficiency.
- Maintain updated knowledge of each model’s capabilities and use cases.
- Create clear classification rules for query types (e.g., medical vs. legal vs. travel).
- Monitor routing decisions to ensure consistent quality and accuracy.
- Start with a small set of models and expand as routing maturity increases.
- Use cost-performance benchmarks to continuously refine routing logic.
- Integrate fallback mechanisms for ambiguous or high-risk queries.
Why This Matters
Dynamic LLM Routing enables organizations to achieve higher accuracy at a lower cost by sending each query to the most appropriate model instead of relying on large, expensive, one-size-fits-all LLMs.
Capabilities at a Glance
|
Area |
|
Without Routing |
With Dynamic LLM Routing |
|
Model Selection |
|
Same model handles all queries |
Specialized model chosen per query |
|
Cost Efficiency |
|
Higher cost due to large context expansions |
Optimized cost through selective routing |
|
Response Accuracy |
|
Varies, may miss domain nuances |
Domain-tuned accuracy via specialization |
|
Scalability |
|
Limited due to compute cost |
Highly scalable with efficient resource use |
|
Context Dependence |
|
Heavy reliance on detailed context |
Minimal context needed for accurate routing |
|
Use Case Performance |
|
Generalistic |
Tailored to domain-specific needs |
Frequently Asked Questions (FAQ)
Q1. What is LLM Routing?
LLM Routing is the process of directing a query to the most appropriate language model based on its intent, domain, and complexity.
Q2. Why is routing necessary when using modern LLMs?
General-purpose LLMs may generate suboptimal responses for domain-specific tasks and incur higher operational costs when given large context windows.
Q3. What are some examples of model specialization?
GPT-4 for creative tasks, Claude for responsible or ethical reasoning, BioBERT for medical language, and Codex for code-related tasks.
Q4. How does routing improve cost efficiency?
By selecting smaller or more specialized models where appropriate, routing avoids overusing expensive, heavy models.
Q5. Are cloud providers using LLM routing today?
Yes. Amazon Bedrock routes seamlessly across Anthropic models and Meta’s Llama models.
Q6. What does a routing system need to function effectively?
Uptodate model profiles, defined routing criteria, and continuous monitoring to validate routing decisions.
Glossary of Terms
LLM (Large Language Model)
A machine learning model trained on massive datasets capable of generating human-like text.
Domain-Specific Model
An LLM trained or finetuned for a particular field, such as medicine, finance, or programming.
Routing System
A logic layer that analyzes queries and decides which model should process them.
Model Profiles
Structured information about a model’s strengths, ideal use cases, limitations, and performance benchmarks.
Context Window
The amount of input text the model can consider during processing.
Best Practices for Implementing Dynamic LLM Routing
- Maintain updated knowledge of each model’s capabilities and use cases.
- Create clear classification rules for query types (e.g., medical vs. legal vs. travel).
- Monitor routing decisions to ensure consistent quality and accuracy.
- Start with a small set of models and expand as routing maturity increases.
- Use cost-performance benchmarks to continuously refine routing logic.
- Integrate fallback mechanisms for ambiguous or high-risk queries.
Common Pitfalls & How to Avoid Them
- Pitfall: Over-reliance on a single, expensive model
Avoid by: Using routing to distribute queries to smaller specialized models. - Pitfall: Poorly defined routing criteria
Avoid by: Establishing clear classification rules and refining them over time. - Pitfall: Outdated model profiles leading to incorrect routing
Avoid by: Regularly updating model capabilities and benchmarks. - Pitfall: Lack of monitoring and audit trails
Avoid by: Adding logging, evaluation frameworks, and human-in-loop checks. - Pitfall: Ignoring new models entering the ecosystem
Avoid by: Continuously reviewing the model landscape as providers release updates.

Solution Architect with extensive expertise in Artificial Intelligence, Machine Learning, and Gen AI systems.
Related reads


About Coforge
We are a global digital services and solutions provider, who leverage emerging technologies and deep domain expertise to deliver real-world business impact for our clients. A focus on very select industries, a detailed understanding of the underlying processes of those industries, and partnerships with leading platforms provide us with a distinct perspective. We lead with our product engineering approach and leverage Cloud, Data, Integration, and Automation technologies to transform client businesses into intelligent, high-growth enterprises. Our proprietary platforms power critical business processes across our core verticals. We are located in 23 countries with 30 delivery centers across nine countries.