
GraphQL is an open-source query language built by Facebook in 2012, that allows users to choose the fields they are interested in. In doing so, it cuts down on the amount of data they receive while executing a query, allowing users to focus on exactly what they need.
GraphQL also helps reduce the time it takes for the transaction to take place. It aggregates the request data and returns only relevant results. This way we need to create less APIs to meet the different needs, adding to the reusability aspect of the APIs.
What you get out of GraphQL?
- Multiple Endpoint Usage Is enabled - There may be multiple APIs to which a single request may span. GraphQL enables a single endpoint for querying data across multiple endpoints. By this way, front end developers are benefitted as they can easily get data and build their APIs faster.
- Over-fetching of data is prevented - GraphQL lets us pre-define what JSON format is the data needed and this helps us get the data returned what is exactly needed with my request. This fastens the application performance and is a key factor for slow internet devices.
- Simple Versioning - Traditional APIs have challenges with versioning and backward compatibility and for that the version needs to be passed in the endpoint or in headers. GraphQL returns only the data that is explicitly requested enabling new capabilities to be added easily.
- Easy Access to Relational Data - The traditional way of obtaining relational data from a data source involves writing SQL queries and joining data across different tables which makes it difficult with nested data with parent-child relationships. GraphQL makes it simple to query data using web standards wherein SQL expertise is not needed to access the data.
- Integration - GraphQL provides an easy-to-use interface to query data from different data sources in a single API call. However, accessing data from different data sources requires robust connectivity and performance that is highly scalable.
MuleSoft can function as the integration layer between the end systems and the GraphQL API that is exposed.
Challenge
There is a REST API that returns 8 fields in response, for both mobile application and Web Application. As per the requirement, the web application expects only 6 fields in response, whereas the mobile application expects only 4 fields. Here, according to the REST API architecture we need to create two endpoints, but with GraphQL we can achieve the above scenario with a single endpoint without any code change.

The above use case can be achieved using two options:
- Anypoint DataGraph Framework (licensed, only for Mule 4)
- MuleSoft GraphQL Connector
Let us explore each option as below.
Anypoint DataGraph
Anypoint DataGraph enables us to connect with the above graphs into one unified schema that runs as a single SaaS (Software as a Service) GraphQL endpoint. It contains all the links and fields defined in the APIs. As a result, we can query across the underlying APIs without needing to understand all the relationships or specific capabilities that exist within them.
It allows us to dynamically query the unified schema and consume the field that is needed to create new connected experiences. This can improve the productivity and reduce operational costs by discovering and reusing the existing data in the application network.
Anypoint DataGraph enables us to:
- Dynamically query data from a unified schema.
- Explore the application network from a single UI.
- Discover, reuse and serve information from the application network without writing new code.
Whenever a new API is added to the application network, Anypoint Platform stores it as a graph of metadata and in turn connects those graphs into one unified schema that runs as a single SaaS GraphQL endpoint and contains and links all of the fields defined within all of the APIs. This helps us query across the underlying APIs without needing to understand all of the relationships or specific capabilities that exist within each of them.
Unified schema:
The unified schema is a single, always-current collection of types from different API schemas that has been added to Anypoint DataGraph and made available for consumers to query. The query type in the unified schema contains all the query methods from the different API schemas that are added to DataGraph. The consumers can access the unified schema to see exactly what data is available to them, all in one place, and request a specific subset of that data in a single query.
Anypoint DataGraph provides three additional functionalities to create more clean and connected Unified Schemas:
- Enable collaboration between object types.
- Link object types to create connections between them.
- Merge object types to combine similar types to a single type to extend their fields and datasets for a more enriched query result.
Some Restrictions and Limitations of Anypoint DataGraph:
Anypoint DataGraph can support:
- REST APIs with RAML and OAS Specifications
- GET Methods with uptp 250 APIs per Unified schema.
- Upto 16000 fields per unified schema.
Anypoint DataGraph limits the downstream API calls to:
- A maximum of 150 concurrent or ongoing calls per unified schema.
- A 5 second timeout per call.
- A maximum of 5 MB of response data per call.
Adding GraphQL Queries
Unified Schema in DataGraph:

GraphQL Query in DataGraph:

GraphQL Query Result:

MuleSoft GraphQL Connector
SQL Centric MuleSoft connectivity to GraphQL
The GraphQL Connector for MuleSoft includes a robust SQL engine that simplifies data connectivity and allows users to accomplish complex data manipulation without extensive transformation workflow.
- Write SQL, get GraphQL data that is similar to the MuleSoft Database Connector, but for GraphQL.
- Powerful SQL Engine with support for dynamic queries, streaming, bulk operations, metadata discovery, query folding, etc.
The GraphQL MuleSoft Connector provides the easiest way to connect with GraphQL data from MuleSoft workflow. The Connectors leverage a straightforward design, similar to the MuleSoft Database Connector, that makes it easy to import, export, backup, analyze, transform, & connect-to the GraphQL data.
It is also a fully-integrated standard Connector featuring seamless integration with the Anypoint designer, dynamic input and operation through DataSense, support for complex projections, streaming, bulk operations, etc. It supports standard SQL queries to interact with GraphQL, just like working with any RDBMS. Supports joins, updates, aggregation, etc.
Normal DB Query | Select With Inner Join | Query for Aggregated Data:
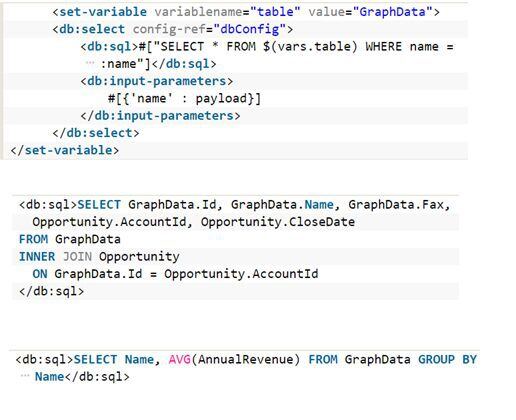
Key Features of GraphQL Connector:
- Data Centric Operations – SQL Access to Data. These connectors functions in a similar way to Anypoint Connectors for Database. They interoperate with MuleSoft DataWeave to offer dynamic data access from MuleSoft workflow.
- Fully Dynamic Queries. Users can parameterize all parts of the Query passed to the Connector. This capability includes the WHERE clause as well as the ability to parameterize parts of the query itself.
- Streaming and Bulk Operation. Connectors support data streaming and bulk operations by default, making operations over large datasets fast and efficient. The connectors include integrated paging that streamlines data access, and support bulk and batch operations for reading and writing.
- Intelligent Query Folding. Improved performance through intelligent query folding. Connectors push data operations server-side wherever possible to improve execution performance. Operations that cannot be executed server side are handled client-side by the robust embedded SQL Engine.
- Metadata Discovery. Extensive schema discovery capabilities. Explore tables, columns, keys, and other data constructs based on user identity.
- Replication and Caching. The connectors’ replication and caching commands make it easy to copy data to local and cloud data stores such as Oracle, SQL Server, Google Cloud SQL, etc. The replication commands include many features that allow for intelligent incremental updates to cached data.
- String, Date and Numeric Functions. Includes a library of 50 plus functions that can manipulate column values into the desired result. Popular examples include Regex, JSON, and XML processing functions.
- Collaborative Data Processing. Connectors enhance the data source's capabilities with additional client-side processing, when needed, to enable analytic summaries of data such as SUM, AVG, MAX, MIN, etc.
- Customizable and Configurable. Data models can easily be customized to add or remove tables/columns, change data types, etc. without requiring a new build. Customizations are supported at runtime using human-readable schema files that are easy to edit.
- All-in-one deployment. It is like other standard MuleSoft Connectors that can be easily deployed to any supported MuleSoft platform.
Sample GraphQL Schema:

If you would like to find out more about how you can enhance API reuse and speed up operations, we can help. Give us a call or email us at Salesforce@coforge.com.
Other useful links:
API Recipes with MuleSoft Anypoint Platform - Mule 4 edition

Related reads.


About Coforge.
We are a global digital services and solutions provider, who leverage emerging technologies and deep domain expertise to deliver real-world business impact for our clients. A focus on very select industries, a detailed understanding of the underlying processes of those industries, and partnerships with leading platforms provide us with a distinct perspective. We lead with our product engineering approach and leverage Cloud, Data, Integration, and Automation technologies to transform client businesses into intelligent, high-growth enterprises. Our proprietary platforms power critical business processes across our core verticals. We are located in 23 countries with 30 delivery centers across nine countries.