
This article demonstrates how we can exploit the power of Kubernetes to build a multi-broker Kafka cluster in minutes using Strimzi. To start, we look at a brief introduction to Apache Kafka and Strimzi before walking through on creation of the Kafka cluster.
Apache Kafka
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications. It can linearly scale with multiple producers and consumers in real-time. Before making a decision, many development teams want to run a pilot to confirm if Kafka is the right fit to solve their problem and if so, want to adapt it for production workload at scale quickly. However, setting up the platform and optimally managing the operations require specialised skills and time for testing and tuning. To address these needs, using Kafka Operators in Kubernetes is an excellent approach.
Kubernetes
Kubernetes is an open-source system for automating deployment, scaling, and managing containerised applications. Kubernetes can manage both stateful and stateless applications at scale. For handling the stateful applications, you use Kubernetes Operators.
Kubernetes Operators are software extensions that use custom resources to manage applications and their components. The operator extends the Kubernetes API via technology-specific objects and orchestrates the management life cycle. Engineers don’t require in-depth knowledge to get started on Kubernetes, as an operator is responsible for implementing and managing the underlying application out of the box. Out of a few available Kubernetes Operators for Kafka, Strimzi is one of the best.
Strimzi
Strimzi is an open-source project that simplifies the process of running Apache Kafka in a Kubernetes cluster by providing container images and Kubernetes operators. Strimzi Operators are fundamental to the running of Strimzi. The Operators provided with Strimzi are purpose-built with specialist operational knowledge to manage Kafka effectively. Operators greatly simplify administration tasks and significantly reduce manual intervention. Strimzi also offers features to enable authentication, authorisation, and the use of custom certificate authority. As part of its abilities, Strimzi can run on plain Mikube or managed Kubernetes environments like AWS EKS or RedHat OpenShift.
To help manage the applications and their components, you can use the various operators that Stimzi bundles for managing a kafka cluster running within a Kubernetes cluster.
Cluster Operator
Deploys and manages Apache Kafka and Zookeeper clusters, Kafka Connect, Kafka Mirror-Maker, Kafka Bridge, Kafka Exporter, and the Entity Operator.
Entity Operator
This comprises of the Topic Operator and the User Operator.
Topic Operator
Manages Kafka topics.
User Operator
Manages Kafka users.
The Cluster Operator can deploy the Topic Operator and User Operator as part of an Entity Operator configuration simultaneously as a Kafka cluster.
Operators within the Strimzi architecture
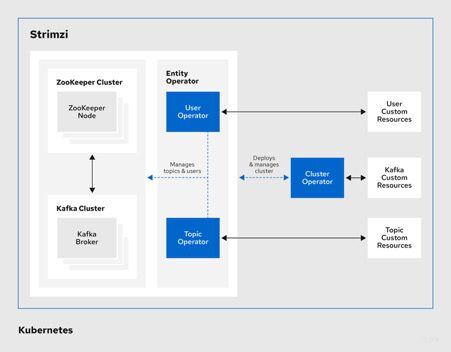
In Kubernetes, Custom Resources are extensions of the Kubernetes API and are added to the existing Kubernetes resources as API instances. Custom Resources (CRDs) can be represented as YAML configuration files and can be referred to for the installation or updating of the resource. Strimzi provides such highly configurable CRDs for Kafka components.
Installing Strimzi
First, install Strimzi with the operators via “kubectl create” in a favourite Kubernetes namespace. The CRDs define the schemas used for declarative management of the Kafka cluster, Kafka topics and users. This enables us to use the custom resources to abstract and manage the clusters.

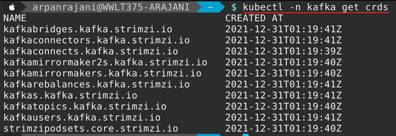
Notice the CRDs created in the Kafka namespace by “kubectl -n kafka get crds”
Once the Strimzi CRDs are created, use these custom resources and provision the Kafka cluster using “kubectl apply -f https://strimzi.io/examples/latest/kafka/kafka-persistent-single.yaml -n kafka”

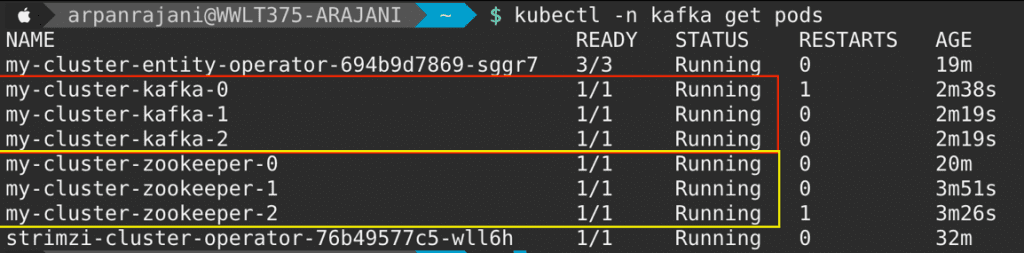
Notice that it has deployed the Strimzi’s operators and Zookeeper and Kafka broker pods. We can list them using “kubectl -n kafka get pods”

You can see that our Zookeeper and Kafka pods are running, and hence the Kafka cluster is running.
Modifying number of brokers/zookeeper instances
The above example shows that it runs only one pod for Kafka and Zookeeper each. It is straightforward to change the number of instances by updating the CRD of the cluster.
Update the replicas from 1 to the desired number in the Cluster CRD using “kubectl edit kafka /my-cluster -n kafka”. The following example shows we are changing the number to 3.
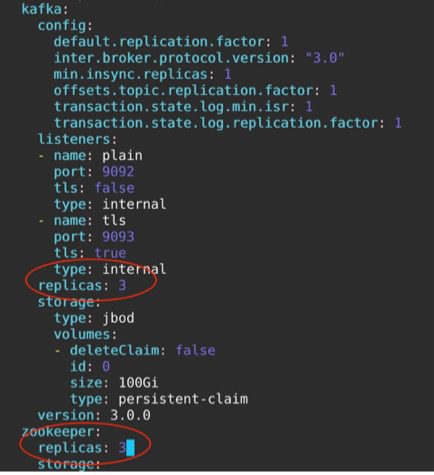
This spawns two more Zookeepers and two more Kafka pods within a few seconds. Getting confirmed after just a few seconds of editing the Kafka CRD.
Note that the default example CRD can be found in the Strimzi’s GIT repository.
Creating and listing topics
Once the cluster is up and running, we can create the topics using CRDs. Example CRD of a topic is found in the Strimzi’s GIT repository. The “KafkaTopic” CRD is used to create and configure topics like replication factor, number of partitions, retention time, etc. When we make, modify or delete a topic using the “KafkaTopic” CRD, the “Topic Operator” performs those changes on the Kafka cluster.
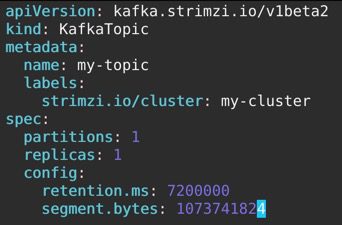
Execute “kubectl apply -f <topic-file.yaml> -n kafka” and it will create a topic on the cluster.

To list the topics in the cluster run “kubectl get kafkatopic -n kafka” or “kubectl gt kt -n kafka”

I hope you enjoyed reading about how we can bootstrap a multi-broker Kafka cluster on Kubernetes using Strimzi.
If you would like to find out more about how Kubernetes can benefit your business, email us at salesforce@coforge.com.

Related reads



About Coforge
We are a global digital services and solutions provider, who leverage emerging technologies and deep domain expertise to deliver real-world business impact for our clients. A focus on very select industries, a detailed understanding of the underlying processes of those industries, and partnerships with leading platforms provide us with a distinct perspective. We lead with our product engineering approach and leverage Cloud, Data, Integration, and Automation technologies to transform client businesses into intelligent, high-growth enterprises. Our proprietary platforms power critical business processes across our core verticals. We are located in 23 countries with 30 delivery centers across nine countries.