

Though the existing Big Data systems are performing well to cater to the huge data volumes that are currently being analysed on a day to day basis, with ever increasing data volumes and with data sources generating newer forms of data, there is always a need to build smarter and more intelligent systems.
New Enhancements
The latest release from Hortonworks, HDP 3.0, has some futuristic enhancements to cater to evolving requirements in data storage and processing. Some of the new components include Apache Superset 0.23 technical preview (modern enterprise-ready business intelligence web application) and Druid 0.10.1(open-source analytics data store). We can also see new replacements, like Hortonworks Dataflow instead of Apache Flume and Ambari Views instead of Hue, as well as the incorporation of Apache Slider functionality in Apache YARN.
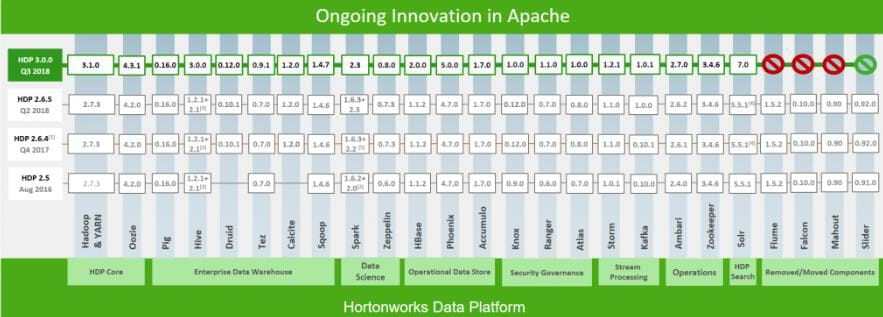
The enhancements for HDP 3.0 are NameNode federation, Erasure Coding, real-time database with Hive 3.0, deep learning framework with containerised TensorFlow, and Cloudbreak for easy provisioning of clusters in the cloud. In the next sections, we talk more about each of these enhancements.
HDFS Erasure Coding
The core component of Hadoop HDFS in HDP 3.0 has a new feature added, the Erasure Coding Encoding. With this we can reduce storage overhead by approximately 50% with the same durability as with replication.
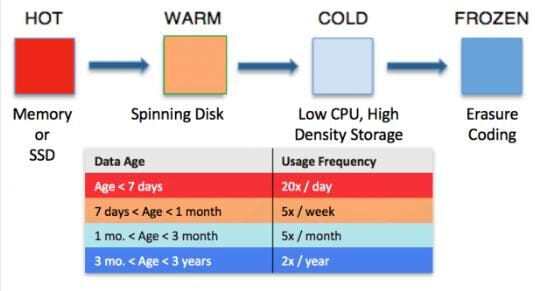
This is a process for encoding a message with additional data, so that if a portion of the encoded message is lost or corrupted, still the original message can be recovered. Let’s say we have a block of data that contains m bits of data. We can encode it into a longer message of size n so that the original message can be recovered from a subset of that n bits of data. XOR encoding can be used for the recovery process in a RAID-5 array.
B1 =[00110100]
B2 =[01011011]
Bp =[01101111]=B1 B2

In RAID the blocks are stripped in an array of physical disks, where one is used to store the parity. In the array of 3 disks, 2 blocks will be actual data and the third is a parity block which is derived as the XOR of the two blocks. We can tolerate the failure of any one drive, as blocks are stored on three different physical drives.
The other algorithm used in EC implementation is Reed-Solomon. This uses two parameters k and m, where k is number of blocks of data to be encoded and m is derived parity blocks. This is referred as RS(k,m)
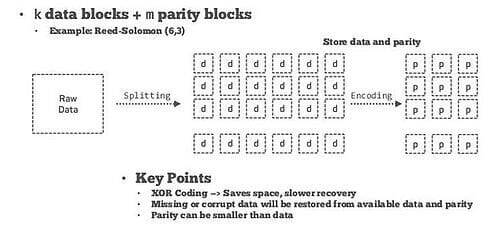
Reed-Solomon algorithm
The implementation had been broken into two phases: in the first phase, the directories in HDFS can be marked as an EC zone and any data written into these directories will be encoded. In the second phase, we can automatically move the EC zone to a standard HDFS tier via a storage policy and the HDFS mover tool. Reed-Solomon algorithm can also perform data locality for larger files.
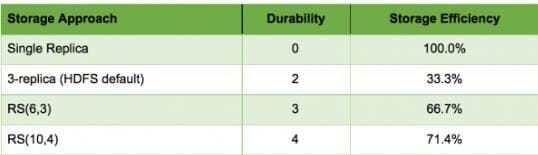
Durability & storage efficiency comparison
When using the Reed-Solomon algorithm we must also consider factors like network bisection bandwidth and fault-tolerance at the rack level.
Use Cases
- Archival Storage: When raw data is ingested from various sources for ETL operations and is stored in another repository, this stored data is infrequently used but we don’t want to delete it as we might need to reuse the ingest pipeline. So instead of keeping 3 replicas we can keep this data in EC zone.
- Backup and Disaster Recovery: To implement DR, storing data in geographically separate clusters is preferred and our cluster does not need to operate with an expensive 3 tier replication. So data can be persisted to an EC zone and can be moved based on needs.
Dual Standby Namenodes
It supports two standby NameNodes for NameNode high availability. If one standby NameNode goes down, we have the benefit of the second standby NameNode, which grants continuous operation. Yarn also features a new timeline service (v2) which improves scalability and reliability.
HBase Features
HBase includes Procedure V2 where we can execute multi-step HBase administrative operations like hbck tool to identify failure scenarios and procv2 to create, modify and delete tables within the failure scenarios. Additionally, while performing Put Operations, the cell objects do not enter JVM heap until the data is flushed into an HFile, helping reduce total heap usage of a Region Server making it more efficient. In-memory compactions are responsible for the periodic reorganisation of the data in the Memstore that can result in a reduction of overall I/O, which is data written and accessed from HDFS. The net performance increases when we keep more data in memory for a longer period of time.
HBase also provides better dependency management, by shading internally incompatible dependencies.
Hive Features
With an LLAP-enabled environment, Hive can support a materialised view. The metadata of the database can be viewed via Hive SQL interface. New connectors like hive warehouse Connector for spark and JDBC storage connector are being integrated. ACIDv2 is released with performance improvements in both storage format and execution engine
Kafka Features
With upgraded Kafka, we can capture producer and topic partition level metrics. In Knox, SSO supports Zeppelin, YARN, MR2, HDFS and Oozie. There is also an added proxy support for YARN, Spark History Server, HDFS, MR2, Livy and SmartSense. Oozie now supports Spark2. A lot of features like Spark jobs can be run in Docker Container and beeline support for Spark thrift server. Now Storm supports Hive, HBase and HDFS.
Druid Features
Druid is an open-source analytics data store designed for business intelligence (OLAP) queries on event data. Druid provides low latency real-time data ingestion, fast data aggregation and flexible data exploration. Current deployments have scaled to trillions of events and petabytes of data.
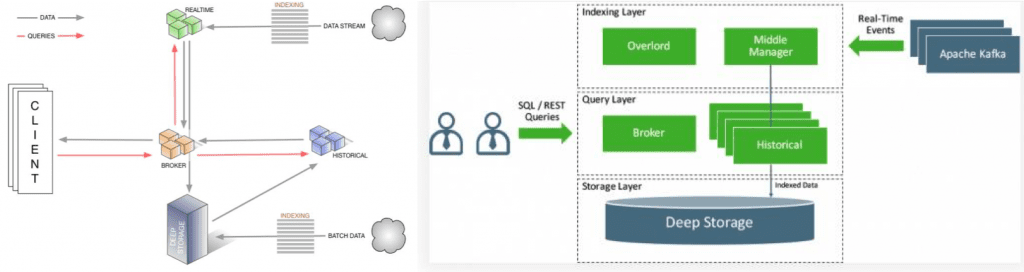
In the new enhancements, Kafka topic can be mapped into a Druid table. In near real-time, the events will be automatically ingested and available for querying.
YARN
YARN has tons of features with a new, user-friendly YARN web UI, Timeline Service V2, support for dockerised Spark jobs, CloudBreak integration and Slider functionality. GPU (Scheduling/Isolation) information is added to the new YARN web UI, whereas an Application timeout feature and App Priority scheduling are added to Capacity scheduler. Now, there is no need to restart the Resource manager after deleting queues. We can enable Capacity Scheduler preemption by default. HDP has evolved in cloud deployments, and it includes support for S3, Google Cloud Storage and Azure. With this, clients can adopt a hybrid data architecture with all cloud providers.
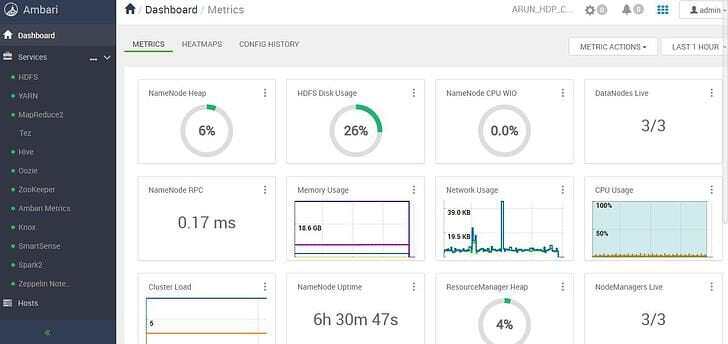
New Ambari Dashboard
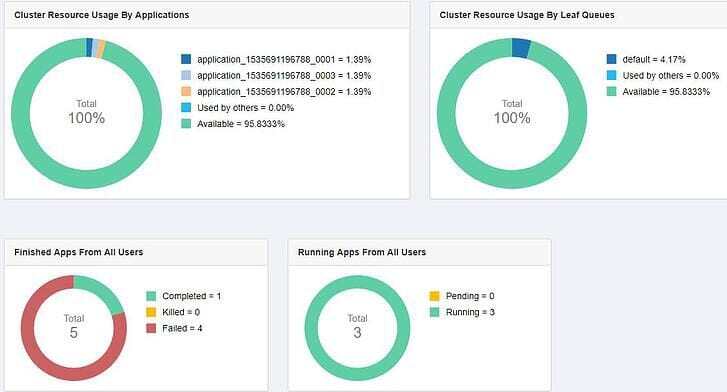
New Resource Manager web UI
Machine Learning & Deep Learning
HDP 3.0 supports deep learning and machine learning with the help of GPU (Graphical Processing Unit) pooling. GPU pooling helps in sharing GPU resources with more workloads and with GPU isolation, GPUs are dedicated to an application.
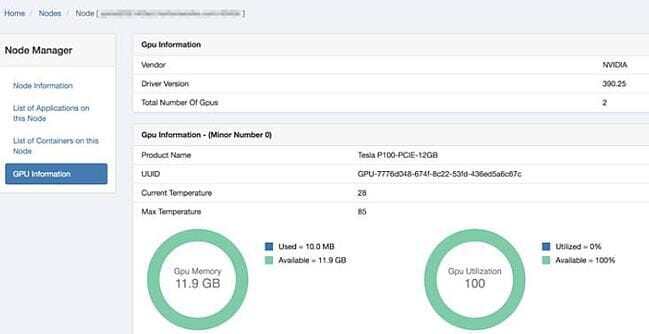
GPU pooling and isolation on apache YARN
Use Cases
Artificial intelligence is embedded into autonomous self-flying drones which can adjust and navigate through obstacles. With the evolving requirements in the self-navigated systems, there is a need for parallel compute processing and deep learning software frameworks. Huge amounts of data in a scale of Exabyte, need to be processed on a near real-time basis. This data is stored in a Hadoop data lake with erasure coding and multiple Standby Namenodes. GPU (Graphical processing unit) cards can be pooled across the cluster for access by multiple data scientists and these GPU cards can be isolated for sharing among multiple users. GPU Pooling increases the speed and are almost 100x faster than the regular CPUs.
Containerisation provides isolation and packaging of workloads. It also helps us lift deep learning frameworks like TensorFlow (C++, Python, Java, Spark) and Caffe on the Spark environment, to bring data-intensive microservices architecture to a native YARN services API.
Cloud Optimisation
The new release of HDP includes support for all major cloud providers like AWS, Azure, Google Cloud and OpenStack. Clients can now use Cloudbreak in deployment of Hortonworks platforms in cloud environments while optimizing the use of cloud resources.
Cloudbreak application is a web application which simplifies HDP cluster provisioning in the cloud.
Cloudbreak WebUI
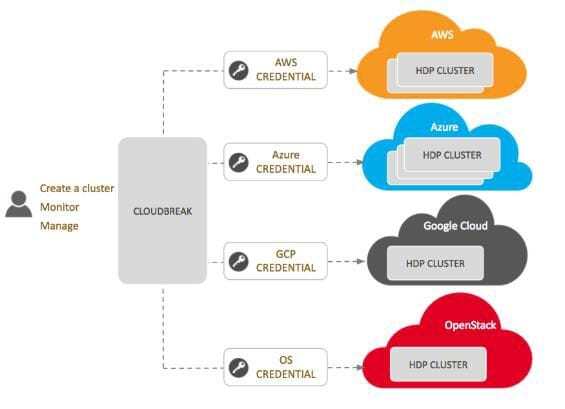
Cloudbreak architecture
Cloudbreak is built on cloud provider APIs, Cloudbreak credential and Ambari blueprints.
Conclusion
Hortonworks with HDP 3.0 achieves to incorporate many new features with a key focus on deep learning and data science. In addition, components like TensorFlow and Cloudbreak significantly speed up the process of Big Data engagements.
At the end, the Big Data community is reinventing itself, with Hadoop becoming more intelligent and powerful!
If you would like to find out more about how Big Data could help you make the most out of your data while enabling you to open your digital horizons, do give us a call at +44 (0)203 475 7980 or email us at Salesforce@coforge.com
Other useful links:

Related reads.

About Coforge.
We are a global digital services and solutions provider, who leverage emerging technologies and deep domain expertise to deliver real-world business impact for our clients. A focus on very select industries, a detailed understanding of the underlying processes of those industries, and partnerships with leading platforms provide us with a distinct perspective. We lead with our product engineering approach and leverage Cloud, Data, Integration, and Automation technologies to transform client businesses into intelligent, high-growth enterprises. Our proprietary platforms power critical business processes across our core verticals. We are located in 23 countries with 30 delivery centers across nine countries.